こんにちは。CTOのzoo(YOUTRUST/Twitter)です。
2023年4月3日から4月7日まで、『めざせChatGPTマスター』と題して5日間の社内ハッカソンを行いました。 最終日の発表会には、外部から審査員をお招きし、全社員の3分の1以上のメンバーが聞きにきてくれて、非常に盛り上がりました!! この記事では、その様子を紹介したいと思います。
ちなみに、勢いで『めざせChatGPTマスター』と題したものの、実際にはOpenAIのAPIを用いたハッカソンです♪
ハッカソンの目的
世の中の多くの企業と同様に、AI系のツールを一人一人が使いこなせるようになることが重要であると考えており、全社員にAIラーニング費用の支給をしていたりします。
そんなYOUTRUSTですが、今回のハッカソンでは次の2つを目的としました。
審査員をお招きしました
ハッカソンなので、最終日には発表会を行いますが、発表会には、「すえなみチャンス」で有名な末並さんとROUTE06の矢野さんにご参加いただき、審査をしていただきました。
外部の方をお呼びすることで、利用者の方をより向いたモノづくりができると思い、お二人に参加いただきました。
余談ですが、素敵なお二人とお話したい方はぜひカジュアル面談に「話を聞きたい」をしてください。
アイデア紹介!!
それでは、実際に開発したものを紹介していきます! ルールは、OpenAIのAPIを用いた機能を開発することです。 なお、今回のハッカソンでは業務上のデータは利用しておりません。
今回、審査員の2人が欲しいと思ったものを選んでもらいました。まずはそれらから見ていきましょう。
ここからは、開発者に自身のアイデアを紹介してもらいます。
【矢野賞】 職務経歴書PDFから自己紹介文を自動生成する機能 by ジョニー
プロフィールの自己紹介を職務経歴書から自動生成する機能を作りました!
職務経歴書に記載の情報をいい感じに要約して自己紹介文を生成しています。
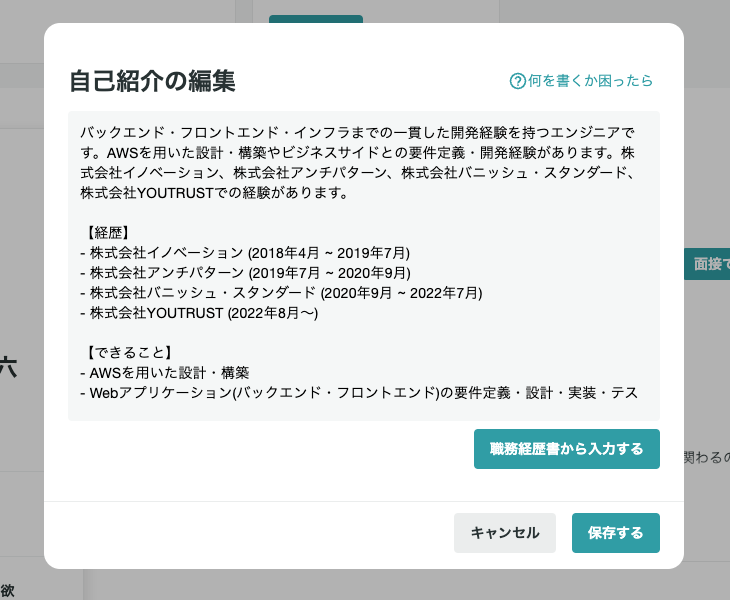
※入力の職務経歴書は私自身のものを使用しました。職務経歴書の内容は割愛させていただきます
技術的なお話
技術選定
PDF→テキストの変換はGoogle Cloud Vision APIのOCR解析で実現しました。 pdf-readerというPDFを解析するライブラリの使用も検討したのですが、精度を考えた時にOCR解析の方が良さそう!と考えOCR解析を採用しました(ここだけの話、OCR解析の方がカッコ良いというのが本心です!!)
OCR解析サービスは色々あると思うのですが、契約などの手続きを考えたときに自社ですでに使用しているAWSかGCP内のサービスを利用するのが楽そうということでこの二つを対象に調査しました。 調査したところAWSにはAmazon TextractというOCR解析サービスがあることは分かったのですが、日本語の解析が対応していないということだったので結果的にGCPのGoogle Cloud Vision APIを使用することにしました!
実装
まず初めにPDFのOCR解析のコードです。言語はRubyを使用しています。
入力のPDFファイルをGoogle Storageに格納し、そのファイルを対象としてアノテーションを行っています。
class GoogleCloudVisionApiClient::AnnotateFile attr_reader :operation_user, :file, :image_annotator, :bucket, :annotated_text def self.call(**args) new(**args).call end def call uploaded_file = upload_file_to_gs files_request = build_annotate_files_request(uploaded_file) response = image_annotator.batch_annotate_files(files_request) response.responses.map { |res| res.responses.map { |r| r.full_text_annotation.text } }.flatten.join("\n") end private def upload_file_to_gs bucket.create_file(file.path, "annotate/#{operation_user.encrypted_id}/#{Time.current.to_i}_#{File.basename(file.path)}") end def build_annotate_files_request(gs_file) gs_util_uri = build_gs_util_uri(gs_file.name) gcs_source = Google::Cloud::Vision::V1::GcsSource.new(uri: gs_util_uri) input_config = Google::Cloud::Vision::V1::InputConfig.new(gcs_source: gcs_source, mime_type: gs_file.content_type) feature = Google::Cloud::Vision::V1::Feature.new(type: :DOCUMENT_TEXT_DETECTION) request = Google::Cloud::Vision::V1::AnnotateFileRequest.new(input_config: input_config, features: [feature]) Google::Cloud::Vision::V1::BatchAnnotateFilesRequest.new(requests: [request]) end def build_gs_util_uri(file_path) "gs://#{bucket.name}/#{file_path}" end def initialize(operation_user:, file:, bucket:) @operation_user = operation_user @file = file @image_annotator ||= Google::Cloud::Vision.image_annotator @bucket bucket end end
次に解析した職務経歴書の内容を元に自己紹介文を作成する処理です。 ここから本題のChatGPTの活用に入ります。
先ほど作成したOCR解析処理を呼び出して返ってくる文章を要約しています。
class RecommendIntroductionContentByResumeFileQuery include QueryRunnable attr_reader :operation_user, :file def run annotated_text = fetch_annotated_text build_recommend_introduction_content(annotated_text) end private def fetch_annotated_text GoogleCloudVisionApiClient::AnnotateFile.call( operation_user: operation_user, file: file, ) end def build_recommend_introduction_content(annotated_text) system_message_content = <<~TEXT 職務経歴書をお渡しするので内容を要約した魅力的な150文字程度の自己紹介文を記載して下さい。 さらに、【経歴】でグルーピングした箇条書きの各企業の在籍期間と、【できること】でグルーピングした箇条書きのスキルに関するキーワードを記載して下さい TEXT result = OpenaiClient.client.chat( parameters: { model: 'gpt-3.5-turbo', messages: [ { role: 'system', content: system_message_content }, { role: 'user', content: annotated_text }, ], temperature: 0, }, ) result['choices'][0]['message']['content'] end def initialize(operation_user:, file:) @operation_user = operation_user @file = file end end
プロンプトは以下のようにしています。
職務経歴書をお渡しするので内容を要約した魅力的な150文字程度の自己紹介文を記載して下さい。 さらに、【経歴】でグルーピングした箇条書きの各企業の在籍期間と、【できること】でグルーピングした箇条書きのスキルに関するキーワードを記載して下さい
職務経歴書の要約と経歴、できることを生成するように指示しています。 これで自己紹介文は完成です。
あとは生成した文章をAPIで返却するだけです。
【末並賞】 投稿内の外部リンクを自動的に要約&表示する機能 by やまでぃ
ユートラへの投稿内に含まれたURLの中身の要約を自動で表示します。
こちらは矢野さんのインタビュー記事の要約例です。
https://www.dodadsj.com/content/220728_route06
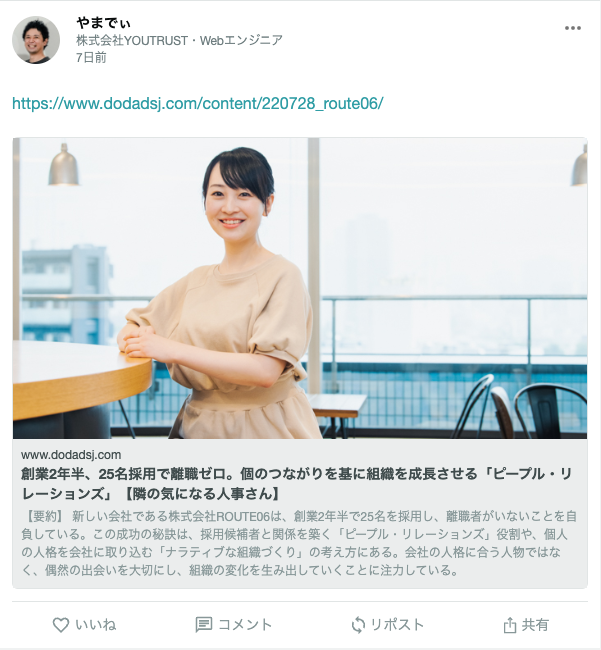
タイムラインにはいろいろなURLをシェアしている投稿が並びますが、ちょっとした隙間時間などでそのすべてを読むのは大変だと思います。 そこで、URLの中身を数行に要約した文章を表示することにより、その負荷を軽減し、情報収集効率を高められないかと思い、今回機能実装してみました。
以下が要約部の実装です。 事前に取得したURLの中身を適切なトークン数に絞り込んで、Open AI APIへリクエストを送信しています。
class AI::Client def self.client @client ||= OpenAI::Client.new( access_token: ENV.fetch('OPENAI_API_KEY'), ) end def self.summarize(content:) response = client.chat( parameters: { model: 'gpt-3.5-turbo', messages: [ { role: 'user', content: <<-PROMPT 次の文章を要約してください。 #{adjust_by_token(content)} PROMPT }, ], }, ) response.dig('choices', 0, 'message', 'content') end # Open AIに渡すトークン数を雑に調整しています。(要改善) def self.adjust_by_token(content) enc = Tiktoken.encoding_for_model('gpt-3.5-turbo') adjusted_tokens = enc.encode(content) ratio = 3000.0 / adjusted_tokens.size slice_count = (content.size * ratio).to_i content.slice(0, slice_count) end end
コミュニティ画像自動生成くん by jun
YOUTRUSTにはコミュニティ機能があります。 コミュニティ作成時に、下記画像のように、コミュニティのタイトルと説明文から、カバー画像の候補を6つ生成します。
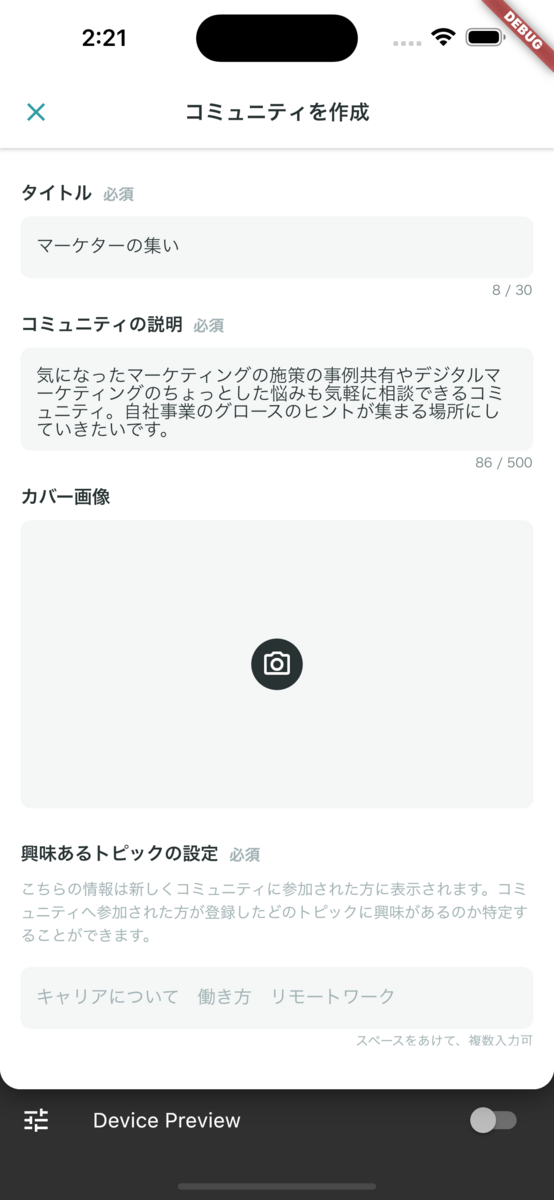

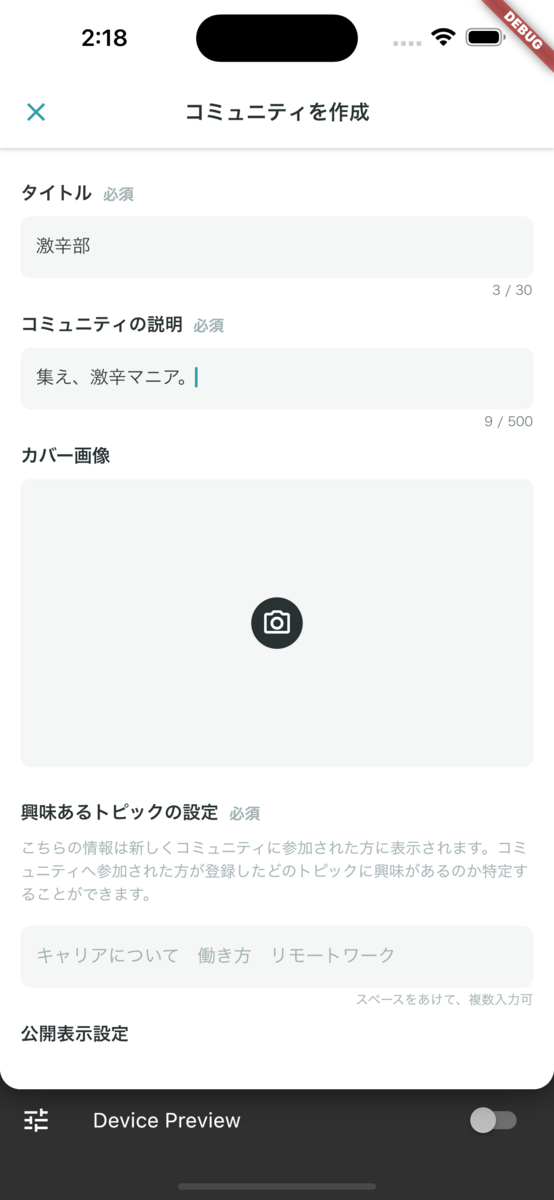

技術的には、次のことをしています。
- コミュニティの
タイトルと説明文からどのような画像をカバー画像とするべきか問い合わせ(問い合わせ用プロンプト)、その画像を生成するためのプロンプトを受け取る - そのプロンプトを元に画像生成を行う
- 2の通信は6件のリクエストを並列で行う
問い合わせ用プロンプト
'あなたは優秀なイラストレーターです。以下はあるコミュニティの説明文です。\n' 'このコミュニティのカバー画像の作成を依頼されました。\n' '制約\n' '- 画像を生成するプロンプトを英語で出力する\n' '- プロンプトは再帰的にチューニングしてGPTで生成しやすいプロンプトにしてください\n' '回答例: Image of four adults enjoying soccer in clear weather. \n' '\n' 'コミュニティ情報' '\nコミュニティ名:$name' '\n説明文:$description',
あなたはどんな人? by 寺井
これまでに同僚や友達から書いてもらった紹介コメントから「まわりの人から見たあなた」を教えてくれる機能を作りました。
紹介コメント機能はもらえるととても嬉しいYOUTRUSTの好きな機能の1つですが、書くきっかけがなかなか生まれづらい一面もあります。
そこで、紹介コメント機能が活性化するきっかけになればと思ってこの機能を作りました。
結果

問い合わせ用プロンプト
以下の文章は、ビジネス上の知り合いに書いてもらった私についての紹介文です。
以下の文章から私がどんな人か要約してください。
ただし、回答は『あなたはまわりの人たちからは、』から始めてください。
1人目からの紹介文は、{support_comment_1.content}です。
2人目からの紹介文は、{support_comment_2.content}です。
...
n人目からの紹介文は、{support_comment_n.content}です。
ユーザーの自己PR文の類似度の算出 by こいちゃん
OpenAIの学習済みの言語モデルで文章を多次元ベクトル化するEmbeddings APIを用いて、ユーザーの自己PRの文章をベクトル化。 ユーザー同士のベクトルを比較することで、ユーザーの類似度を比較できるか試してみました。
テストデータ
Embeddings APIの入力パラメータとなる input はGPT-4で生成した職種に応じた200文字程度の自己PR文を使いました。
- プロンプトの例:「あなたはスタートアップ企業のWebエンジニアです、200文字程度で自己PRしてください。」
ベクトル化と類似度の比較
上記のテストデータをいくつかの職種(CEO, CTO, エンジニア, デザイナー, etc.)に対して準備しそれぞれをEmbeddings APIでベクトル化・類似度の比較を行いました。 ベクトル化するコードはinputに文章を渡すのみです。 - https://platform.openai.com/docs/guides/embeddings/how-to-get-embeddings ドキュメントによるとベクトルの距離を算出するのにコサイン類似度を用いるのがおすすめと書かれていました。 ここではコサイン類似度の値が大きいと比較した文章がより似た傾向を持っていると考えます。 - https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-use
結果
いくつかの職種をすべての組み合わせで比較しましたが、絶対値として大きな差はなさそうでした。 その中でもエンジニア同士やCFOと経理のように近いと思われる語彙を含む職種同士の値は比較的大きく出ていたようにも見えました。 テストデータはGPT-4で生成した文章なので実際の文章ではまた勝手が違うと思いますし、うまくアウトプットを得る前処理などもあり得るかもしれません。 この数値だけで類似度を判断するのは難しいと思いますが、パラメータの1つとして活用する道はありそうだなと思いました。
AIコミュニティーオーナーアシスタント by 天野さん
YOUTRUSTには、コミュニティという機能があります。それぞれのコミュニティはオーナーであるユーザーによって運営されているのですが、その作業はとても大変です。 そこで、AIコミュニティーオーナーアシスタントを考案しました。このアシスタントは、投稿への自動返信やおすすめトピック選出などを自動的に行ったり、コミュニティに沿った記事を要約して投稿しコミュニケーションを促進する、ということをすることができる(想定)です。 今回は、コミュニティに沿った記事の要約を行う際に利用したコードを紹介します。
import { ChatCompletionRequestMessageRoleEnum, Configuration, OpenAIApi } from "openai"; function splitByLength(str: string, n: number) { const regex = new RegExp(`.{1,${n}}`, "g"); return str.match(regex); } const configuration = new Configuration({ apiKey: process.env.OPENAI_API_KEY }); const openai = new OpenAIApi(configuration); const generateSummary = async (text: string, current_summary: string) => { const systemContent = `あなたは文章を要約するアシスタントAIです。userが入力した文章を300字の要約してください。 現段階の要約文が存在している場合は、それの一部を加筆修正する形で300字で要約してください。 また、返答は日本語で行ってください。 現段階の要約はこちらです。 -------------------------- ${current_summary} `; const messages: { role: ChatCompletionRequestMessageRoleEnum; content: string; }[] = [ { role: "system", content: systemContent }, { role: "user", content: text } ]; const response = await openai.createChatCompletion({ model: "gpt-3.5-turbo", messages, temperature: 1, top_p: 1, frequency_penalty: 0, presence_penalty: 0, stream: false, n: 1 }); if (response.status !== 200) { console.log(response?.statusText); throw new Error(response?.statusText); } else { return response.data.choices[0]?.message?.content; } }; async function summarize(text: string) { const input = text.replace(/\n/g, " "); let currentSummary = ""; const inputArray = splitByLength(input, 3000); for (const t of inputArray) { currentSummary = (await generateSummary(t, currentSummary)) || ""; } return currentSummary; }
トークンの上限があるため、GPTを使って要約を作成する際には一度にサマライズできる記事の量に制限があります。 そのため、記事を分割してサマリーを生成することにしました。また、次のチャンクの要約を作成するときは、それまでに作成した要約に追記していく方針を取りました。
このアイデアは、以下の記事を大いに参考にしました。 note.com
スカウトメッセージのフィードバック by zoo
YOUTRUSTでは、企業様からユーザー様にスカウトメッセージを送ることができます。 スカウトメッセージがより良くなることで、送った側も送られた側も、よりハッピーになります。 そこで、スカウトメッセージの下書きに対して、フィードバックを行うことを考えました。
フィードバックではなく、AIがスカウトメッセージを書いてくれる機能もアイデアとしてはあると思います。 しかし、僕個人としては、メッセージの書き手が人であり、人のぬくもりがメッセージに含まれることが大切だと思っています。 そのため、あくまで手助けという位置付けの機能になります。
今回は、4つの評価ポイントに対して、スカウトメッセージにフィードバックをするようにしました。 下記のプロンプトをAPIに送り、返ってきたJSON形式の値をフロントエンドにそのまま返して、フィードバックを表示しました。 GPT3.5だと、フィードバックがいまいちだったのですが、GPT4だと、かなり良い感じにフィードバックをしてくれました。
プロンプト
<<~"MESSAGE" 採用のためのスカウトメッセージを評価する。 回答はフォーマットに従ってJSON形式で行う。 評価は、point1、point2、point3、point4の評価ポイントに対してそれぞれ行う。 評価は、評価ポイントを満たしている場合には合格、評価ポイントを満たしていない場合には不合格とする。 point1: 評価するポイントを詳細に説明 point2: 評価するポイントを詳細に説明 point3: 評価するポイントを詳細に説明 point4: 評価するポイントを詳細に説明 フォーマット: { "point1": { "judgement": "{point1に対する評価をOKもしくはNG}", "reason": "{point1の評価の理由}" }, "point2": { "judgement": "{point2に対する評価をOKもしくはNG}", "reason": "{point2の評価の理由}" }, "point3": { "judgement": "{point3に対する評価をOKもしくはNG}", "reason": "{point3の評価の理由}" }, "point4": { "judgement": "{point4に対する評価をOKもしくはNG}", "reason": "{point4の評価の理由}" } } スカウトメッセージ: #{create_params[:scout_message]} ← ここにフィードバックをするスカウトメッセージをいれます MESSAGE
おわりに
ハッカソンではいろいろなアイデアが披露されました。 エンジニアにとっては純粋にモノづくりを楽しむ一週間でした。 参加してくれたエンジニア以外のメンバーも非常に盛り上がってくれました。 もともとの目的も達成できたと思います。
今回のハッカソンはYOUTRUSTにとってはじめてのハッカソンでしたが、これを機に、今後も定期的にハッカソンを行なっていきたいと思います。
また、AI系のツールを利用していくこと自体は引き続き行なっていきたいと思っており、一定のリソースをそこに割いていきます。 いずれその話もお伝えしたいと思います。
おまけ
審査員として参加してくださった末並さんと矢野さんとエンジニアメンバーで焼肉にいってきました! お二人とも、本当にありがとうございました!!
