こんにちは!YOUTRUSTの春日です。
今年の夏はめちゃめちゃ暑いですね。僕は夏バテ対策と理由をつけて辛い料理をほぼ毎日食べています。 辛いものは食欲増進の効果があるという説もあるので、辛いもの好きの方は共にカプサイシンを摂取していきましょう。
さて、今回は業務でBigQueryのデータをSFTPサーバーに定期バッチ処理で送信する仕組みを作成したので、主にインフラの構成の解説と、作成に至るまでに試行錯誤したポイントについて説明していきたいと思います。
インフラ構成
Google Cloud環境にて、以下のような構成で作成しました。
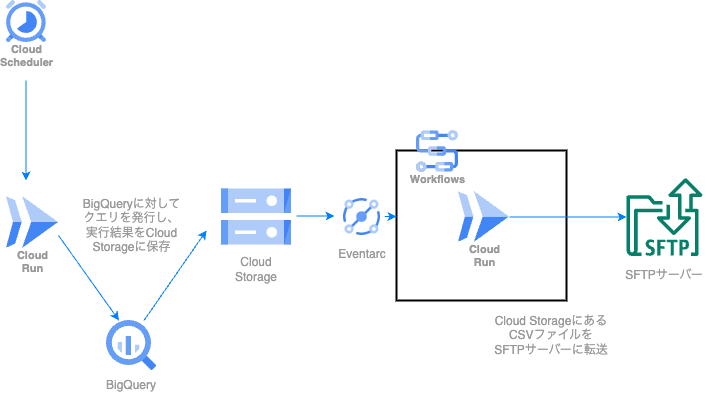
処理の流れを解説します。
1. Cloud Schedulerを毎日特定の時刻に発火
まず最初に、cron式で定義されたタイミングでCloud Schedulerが起動します。 このCloud Schedulerが後続のCloud Run Jobsの起動エンドポイントにPOSTリクエストを投げます。
2. BigQueryのデータをCloud Storageへ格納する関数の実行
Cloud Run Jobsが起動し、関数が実行されます。 BigQueryのクエリを実行して一時テーブルへ格納し、作成された一時テーブルのデータをCloud Storageへ出力します。 正常にエクスポートが完了したら、一時テーブルを削除して処理を終了します。
ここでは一度にエクスポートするデータ量が大きくなりすぎないように上記の処理を複数回に分けて行なっています。
3. Cloud Storageのオブジェクト作成イベントを検知し、二つ目のCloud Run Jobsを起動
Cloud Storageにオブジェクトが格納されたら、二つ目のSFTPサーバー転送用のCloud Run Jobsを起動します。 手順としては、Cloud Storageのオブジェクト作成イベントをEventarcが受け取り、Eventarcがworkflowsを起動します。 その後、workflowsの設定で定義された実行フローに従い、Cloud Run Jobsが実行されます。
4. Cloud StorageのCSVファイルをSFTPサーバーに転送する関数の実行
関数内にて、workflowsから環境変数としてCloud Storageに作成されたオブジェクトのパス情報が渡されるので、その情報を用いてオブジェクトを取得します。 その後、SFTPサーバーへ接続し、ファイルを転送して処理を完了します。
以上のような流れでデータを行うシステムを作成しました。 ここからは、上記の構成に至るまでに試行錯誤したポイントがいくつかあるのでご紹介します。
試行錯誤したこと
BigQueryのデータ出力処理をScheduling queriesで構成しようとした
実のところ、BigQueryのデータを定期的にCloud StorageにCSV形式で吐き出すぶんにはCloud Runを使う必要がありません。
BigQueryにはScheduling queriesというものがあり、これを使うことでBigQueryのクエリを定期実行することが可能になります。
さらにBigQueryのクエリには実行結果をそのままCSV形式でCloud Storageに吐き出すことができるEXPORT DATAステートメントがあり、これらを組み合わせることで定期的にCloud StorageにCSVをエクスポートすることが可能です。
なので、当初はBigQuery -> Cloud Storageのデータ出力を行う部分はCloud Runを使わずScheduling queriesを使う予定でした。 しかし、この構成だとファイル分割の部分で問題が発生しました。
前提として、EXPORT DATAステートメントを使う際は吐き出されるCSVファイルを1GB以内に納める必要があります
*1。
今回対象のデータは1GBを超えていたため、そのまま単一のファイルで吐き出すことができません。
その場合、EXPORT DATAステートメントで吐き出すCSVファイルのファイル名の指定に'*'(ワイルドカード)を含めることで、クエリの実行結果を複数のファイルに分割した形でCloud Storageに格納することが可能になります。
クエリの内容は以下のような形です。
EXPORT DATA OPTIONS (
uri = 'gs://bucket_name/folder_name/data_*.csv
, format = 'CSV' -- 保存する形式
, overwrite = true -- ファイルの上書き
, header = true -- ヘッダー行の作成
) AS
SELECT * FROM ~~~~;
こうすると、クエリの実行結果がファイル分割されて出力されるようになります。 この便利なファイル分割の機能ですが、今回の我々が作成したいシステムの要件と合わない点が二つありました。
一つ目は、生成されるファイル名を完全に制御することができないことです。
前述の通り、EXPORT DATAクエリのuriにワイルドカードを含むことでファイルが分割されますが、分割されたファイル名はdata_000000001, data_000000002....のような形の連番が付与されます。このように生成される連番の形式はこちら側からカスタマイズすることができず、今回のSFTPサーバーに上げるファイル名の要件を満たすことが難しいことがわかりました。
二つ目は、ファイルの分割単位をこちらで制御できないことです。 例えば、2GBの容量のデータを最大容量1GBという制限の元ファイル分割して保存するときに、通常だと1GBのファイル2つに分けて作成されることをイメージしますが、これがuriワイルドカード指定だと数百~数千のファイルに分割されて作成されてしまっていました。こちらも、今回進行する上で不都合となるものでした。
上記の問題があることから、今回は自前で用意した関数でクエリ実行を行い、CSVファイルに出力する形で進行することにしました。*2
Cloud Run JobsではなくCloud Functionsを使おうとした
私は普段AWSをメインとして使用していて、一つの関数を実行するだけであればLambda、それと近似するGoogle CloudのリソースはCloud Functionsだという認識を持っていたため、当然のように今回の関数実行部分はCloud Functionsで構成する認識でいました。 しかし、Cloud Functionsで検証を進めてみると関数実行タイムアウトの点で問題が生じました。 Cloud FunctionsはHTTP関数とイベントドリブン関数の2種類がありますが、イベントドリブン関数だと実行タイムアウトが最大540秒(9分)という制限があります *3。 この制限がなかなか厳しく、数百メガバイトの容量のCSVファイルをSFTPサーバーに上げてみると大きくタイムアウトの時間をオーバーしてしまいました。
そのため、別の手段を検討した結果Cloud Run Jobsを今回採用することにしました。 Cloud Run Jobsはタイムアウトを最大24時間まで延長することができ、今回のケースにまさにマッチしていました。*4
また、別の観点ではありますがリソース作成のフローにおいてもCloud Run Jobsが使いやすいと感じました。Cloud Functionsを作成する際はCloud Storageなどにソースコードをzip化して上げる手順が必要でしたが、Cloud Run JobsはArtifact RegistryにImageを登録するだけで動かせるようにできたことが個人的に良い体験でした。
振り返り
以上、インフラ構成とそこに至るまでの試行錯誤の説明でした!
ファイルサイズの制約や、実行タイムアウトの制約など、扱うデータのボリュームによって色々構成を工夫する必要がありました。
AWS環境のインフラ作成にはある程度慣れていたのですが、今回の機会でGoogle Cloudのインフラリソースについても理解を深めることができて良かったです。
最後に
YOUTRUSTではエンジニアを積極的に採用しています!
様々なポジションで求人を出しているので、ご興味のある方は是非以下の募集をご覧ください!
*1:参考:https://cloud.google.com/bigquery/docs/exporting-data
*2:今振り返ってみると、Scheduling Queriesを使う場合でも頑張ってEXPORT DATAクエリ自体をいい感じに分割して発行するような構文を書ければ同等の機能を実現できたかもしれません。
*3:参考:https://cloud.google.com/functions/docs/configuring/timeout
*4:BigQueryのクエリを発行する関数はCloud Functionsにしても良かったのですが、Cloud Run Jobsでリソースを統一する方が管理しやすいため、二つの関数を両方Cloud Run Jobsで作成することにしました。