こんにちは!YOUTRUSTでデータエンジニアをしている小林(YOUTRUST)です。 入社して4ヶ月が経ち、YOUTRUSTのデータ基盤について理解が進んだので、このタイミングでデータ基盤の構成についてまとめようと思います。データ基盤開発を行っている方の参考になれば嬉しいです!
データ基盤のアーキテクチャ
2025年11月現在、YOUTRUSTのデータ基盤のアーキテクチャはこのような構成になっています。

YOUTRUSTのデータ基盤は下記の技術スタックで構成されています。
- DWH: BigQuery
- Extract, Load: GCS Transfer Job, Cloud Function
- Transform: dbt Cloud
- Reverse ETL* : BigQuery Scheduled Query, dbt Cloud
- CI/CD: GitHub Actions
* Reverse ETLとは、データウェアハウスなどのデータ基盤に蓄積されたデータを業務アプリケーションに連携することを意味します。
データソース
YOUTRUSTのアプリケーションはAWS上にあり、データもAmazon RDSにあります。RDSのスナップショットを日次でS3に書き出しており、それをGCSに転送してBigQueryで読み込んでいます。
また、アプリケーションのログについては、fluentdでS3に1時間に1回書き出されており、こちらも同様にGCSに転送してBigQueryで読み込んでいます。
そのほか、Adjust、Salesforce、GA4、スプレッドシートのデータも取り込んでいます。
データウェアハウス
YOUTRUSTでは、データウェアハウスにBigQueryを活用しています。レイヤリングとしては、データレイク層、ステージング層、コンポーネント層、モデル層、データマート層の5層に分かれています。各層はBigQueryのデータセットで分かれています。
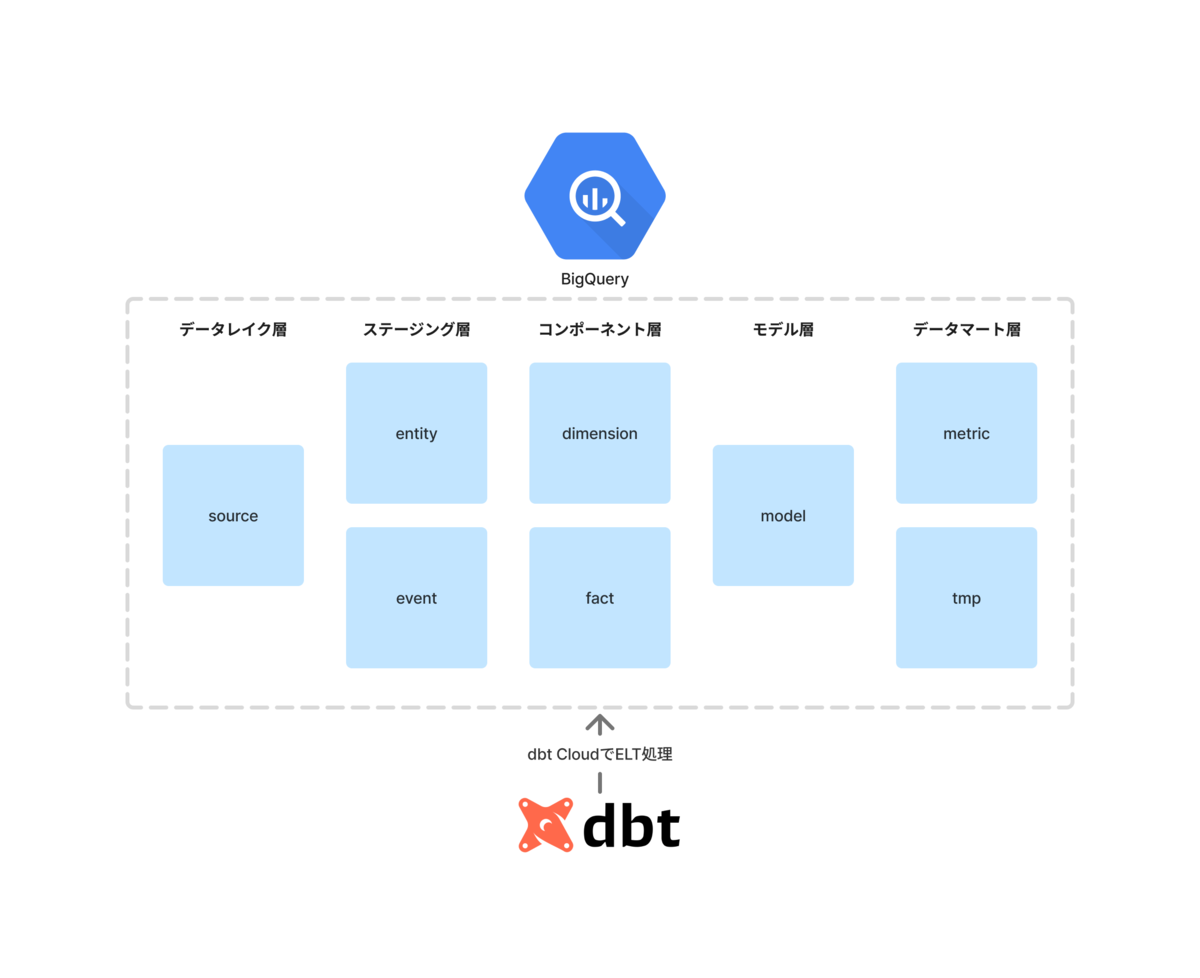
GCSにあるRDSのスナップショットやログをBigQuery上で外部テーブルとして読み込んでいます。このデータたちをデータレイク層として、dbt (dbt Cloud)を用いてデータ整形をしています。
ステージング層は、RDBの生データを分析に使いやすい形に変換したテーブルが置かれています。例えば、以下のような処理をしています。
- BigQueryのSTRUCT型を活用して生のカラムを意味のあるグループにまとめる
- タイムスタンプのタイムゾーンをUTCからJSTに変換する
- 数値のIDにラベルをつける
- データクレンジング (ユーザー名などの暗号化、正規化、NULLの処理)
また、BigQueryのパーティションを使って、RDBスナップショットを遡ることができるhistoryテーブルと最新の断面を見ることができるcoreテーブルの2種類のテーブルを用意しています。これにより、最新の情報が見たいときはcoreテーブルを参照すればよい状態になっています。
コンポーネント層は、ディメンショナルモデリングの考え方をもとに、ディメンション (分析の軸となるもの)とファクト (分析の指標となるもの)のテーブルを作成したものを置いています。例えば、ユーザーの属性を集約したディメンションテーブルやページ閲覧やクリックなどの行動ログを集約したファクトテーブルがあります。
モデル層は、コンポーネント層のディメンションテーブルとファクトテーブルをJOINしたテーブルが置かれています。この層のテーブルを参照することで、複雑なJOINを書かずに基本的なデータ分析が簡単にできるようになっています。
データマート層は、主にBIツール (Metabase、Looker Studio)で接続するためのテーブルが置かれています。
データ活用
YOUTRUSTでは、BIツールとして主にMetabaseを活用しており、一部でLooker Studioを利用しています。Google スプレッドシートのデータコネクタを活用したデータ分析も盛んに行われています。データの分析を経て、プロダクトやマーケティング施策の改善に活かされています。
また、Salesforce Marketing CloudやFirebaseにBigQueryのデータが連携されており、ユーザーへのメールやプッシュ通知の配信に活用されています。
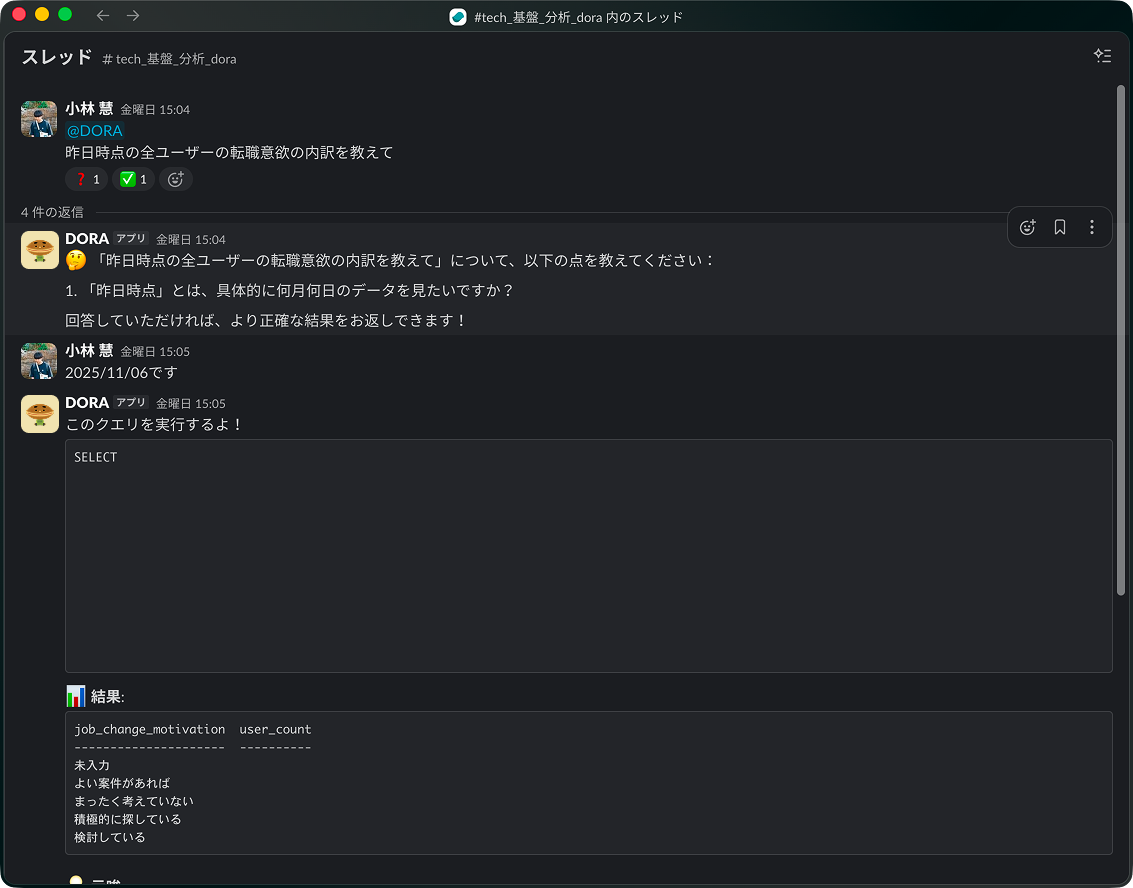
つい最近、データ分析Slack bot「DORA (Data Oracle*1 Responsive Assistant)」がリリースされてSlackから簡単にBigQuery上のデータを分析できるようになりました! まだ完璧な返答が返ってくるわけではありませんが、利用されていく中で改善していく予定です。
まとめ
この記事では、2025年11月時点でのデータ基盤の構成についてまとめてみました。アーキテクチャの図を見るとかなり整っているように見えるかもしれません。しかし、4ヶ月間データエンジニアとして働いてみて、まだまだ課題はたくさんあると感じました。
例えば、
- S3からGCSへのデータ転送処理やdbtの処理が時間をトリガーとしているので、前の処理が終わってないのに次の処理が始まってしまって失敗する
- Descriptionが書かれていないモデルが多くあり、AIで分析させるのがうまくいかない
- dbtのテストが充足していないので、データの品質を完全に担保できていない
などなど…
データエンジニアとしてやっていきたいこと
僕はYOUTRUSTでdbt・データ基盤について一番詳しい人になることをまずは目指しています! そして、データ基盤を整備することで、誰もが簡単にデータ分析できる状態を作りたいと思っています。
そのためにも、上記の課題をひとつずつ解決しながらデータ基盤を「使いやすく、信頼できるもの」にしていきたいと思います!
*1:データ系でOracleといえばOracle Databaseが思い浮かびますが、oracleには「神のおつげ」という意味があるそうです