こんにちは!SRE一年生の墨(YOUTRUST/X)です!
5XXエラーを解消したらサービス全体が高速化した話をしようと思います。
チームで調査を進めた結果、根本原因を特定することができました。
この記事では、問題解決に至るまでの過程についても共有したいと思います。皆様の参考になれば幸いです。
アラート通知
前回のブログで書いた通りDatadogを導入しました。 その際に下記項目の監視を見直したことでインフラアラート用のSlackチャンネルに頻繁に画像の通知が届くようになりました。
- ALBエラー率:3% -> 1%
- ALBレスポンスタイム:平均 -> パーセンタイルで集計

query部分はマスクしています。
おそらく以前から発生していた問題だと思われますが、「オブザーバビリティはまず監視から」が身に染みた出来事でした。
また、ここで悪かったのが、「2, 3分で復活しているのでそこまで緊急度は高くないだろう」と考えてしまったことでした。
重大なエラーを見つけたらまず調査!を徹底したいと思います。
エラー内容の把握
エラー調査はまずエラー内容の把握からということで調べることにしました!
エラーコード
上記のアラート通知からも分かるようにエラーコード毎にアラートやダッシュボードを出し分けていませんでした。
そこでダッシュボードで可視化をすると504 Gateway Timeoutのエラーコードが出ていることが把握できました。
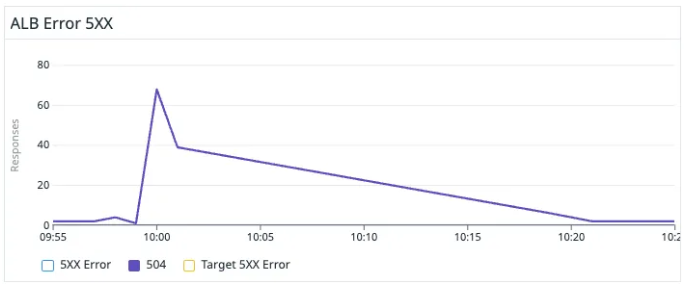
ALBの5XXエラー整理
ALBの5XXエラーにはHTTPCode_ELB_5XX_CountとHTTPCode_Target_5XX_Countがあり、公式ではそれぞれ下記のように記されています。
HTTPCode_ELB_5XX_Count(= ELB 5XXs)
- ロードバランサーから送信される HTTP 5XX サーバーエラーコードの数。この数には、ターゲットによって生成される応答コードは含まれません。
HTTPCode_Target_5XX_Count(= HTTP 5XXs)
- バックエンドに配置されたターゲットによって生成された HTTP 応答コードの数。これには、ロードバランサーによって生成される応答コードは含まれません。
これだけだとターゲットがエラーを吐いていないなら、ALBの基盤のエラーかなと考えてしまいますが、公式ドキュメントにはエラーが発生する理由も丁寧に載っていました。
- HTTP 504: Gateway Timeout
- ロードバランサーはターゲットへの接続を確立したが、アイドルタイムアウト期間が経過する前にターゲットが応答しなかった。
これらのドキュメントからバックエンドとの通信などに問題があるのではと推測し、更なる調査を進めていきます! 下記リンクがまとめられていて参考になりました。 dev.classmethod.jp developers.play.jp
ダッシュボードを読み解く
次にダッシュボードから情報を拾います。
個人的にはダッシュボードを読み解くとは「粒度や期間を変えながら違和感と共通点を見つける作業」だと考えています。
下記画像(30分、6時間)から読み解いてください。
表示時間や集計間隔を変更、比較することで見えなかった問題が見える場合があります。
※ 30分は直前の状況の把握、6時間は傾向の把握に利用しました。
※ 急にタスク数が倍になっているのはローリングデプロイしている時です。
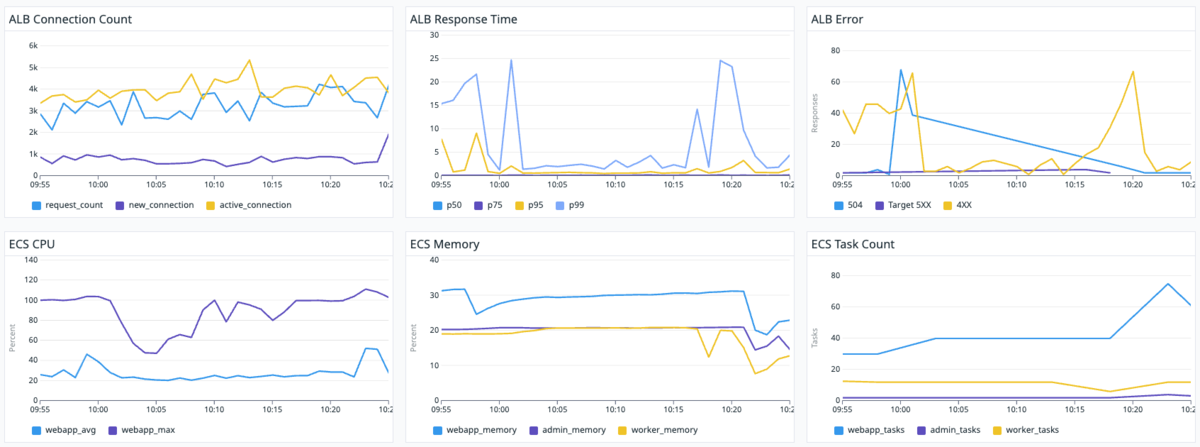
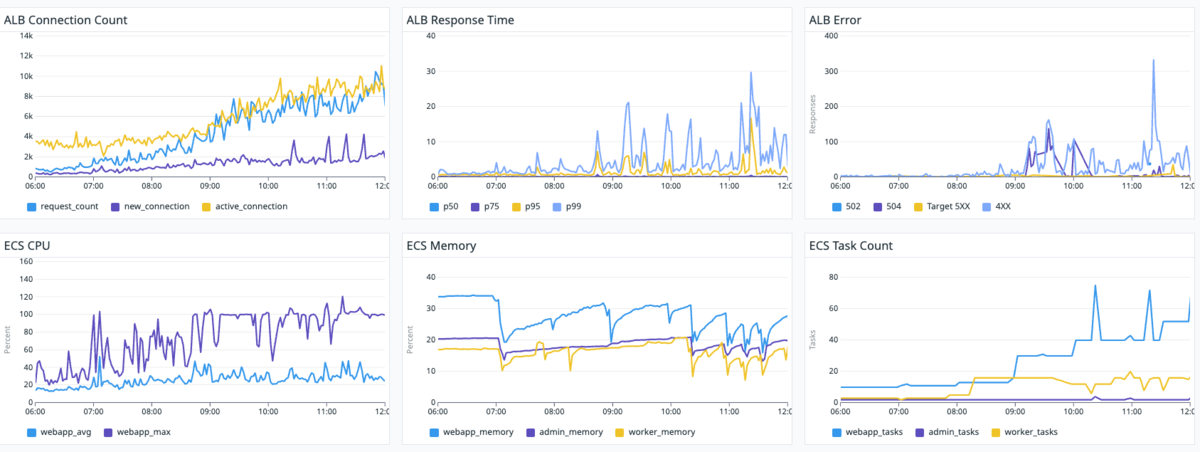
どうでしょうか?以下のことがなんとなーく把握できれば望ましいです! ダッシュボードから情報を広い、裏付けるために更なる調査を行うためなんとなく把握するのが重要だと考えます。
・ タスクをスケールアウトしている時にエラーが出ている?
・ 504が出ている時一緒に4XXも出ている?
・ スケールアウト時はMAX CPUが100%, AVG CPUが50%近くまで上昇している
ログを確認
弊社ではFargateコンテナのRubyとNginxのログをDatadog Logsに送信しています。
該当時間にどのようなエラーが出ているのか確認すると下記2種類のエラーが大量にNginxコンテナから吐かれていました。
# ELBからのヘルスチェックを502エラー(Bad Gateway)で返却したログ 10.0.1.163 - - [03/Mar/2025:01:24:45 +0000] "GET /rack_health HTTP/1.1" 502 157 "-" "ELB-HealthChecker/2.0" "-" # Pumaへの通信で仕様するソケットファイルが見つからないログ 2025/03/03 01:24:45 [crit] 18#18: *6 connect() to unix:/app/tmp/sockets/puma.sock failed (2: No such file or directory) while connecting to upstream, client: 10.0.1.163, server: , request: "GET /rack_health HTTP/1.1", upstream: "http://unix:/app/tmp/sockets/puma.sock:/rack_health", host: "10.0.1.237"
仮設立て
これまでの情報を元にエラーが出ている下記2つの可能性を考えました。
- Pumaの起動時間に問題
- ECSタスク起動時にPumaの起動が遅れたため、Nginxが502エラー(Bad Gateway)を返し、ALBが504を出した。
- ELBのタイムアウト値に問題
- ELBのタイムアウト値が長いため終了後にヘルスチェックが失敗せずコンテナが切り離される前に通信が継続された。
上記推測される問題点を解消するための施策を複数考えました。
- vCPUを増強
- Pumaの設定ファイル見直し
- Nginxの設定ファイル見直し
- コンテナ間の依存関係
- Dockerヘルスチェック
- ELBのヘルスチェック設定見直し
検証、実装
その中から今回は効果の高そうなvCPUを増強とPuma設定ファイルの変更を実装しました。
vCPU増強
タスク全体で0.5vCPUから2vCPUに変更しました。
ダッシュボードからも分かる通り平均で見ると50%程度ですが、MAX値で取ると100%の場合も多く、デプロイ時に特に上がることが読み取れました。
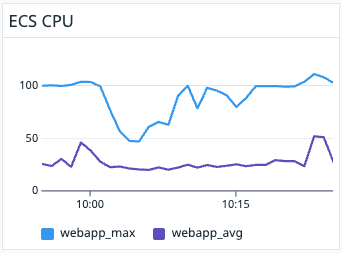
Pumaの設定ファイル見直し
Pumaの起動が遅いためにソケットファイルが見つからずヘルスチェックが落ちているため起動を早めるプリロード設定を追加しました。
また、vCPUを増やしたことでworkerを使用することができるため結果的に設定ファイルは以下となりました。(スレッド:5、ワーカー:2)
max_threads_count = ENV.fetch('RAILS_MAX_THREADS', 5)
min_threads_count = ENV.fetch('RAILS_MIN_THREADS', max_threads_count)
threads min_threads_count, max_threads_count
worker_timeout 3600 if ENV.fetch('RAILS_ENV', 'development') == 'development'
port ENV.fetch('PORT', 3000)
environment ENV.fetch('RAILS_ENV', 'development')
pidfile ENV.fetch('PIDFILE', 'tmp/pids/server.pid')
# 環境変数にてWEB_CONCURRENCY=2を代入
workers ENV.fetch('WEB_CONCURRENCY', 0)
preload_app!
bind "unix://#{Rails.root}/tmp/sockets/puma.sock"
plugin :tmp_restart
実装結果
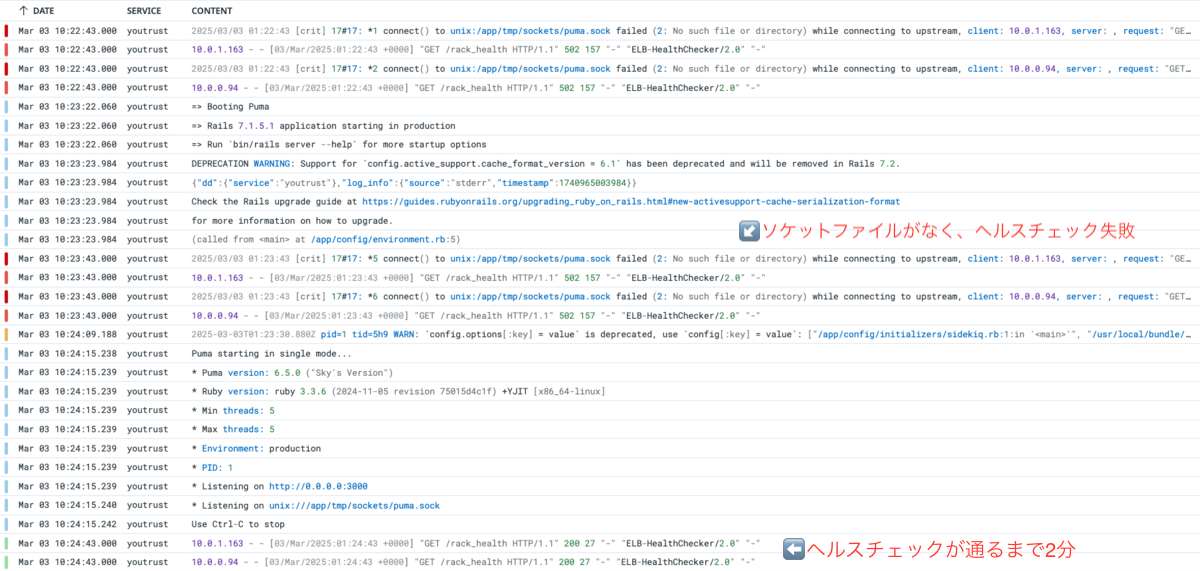
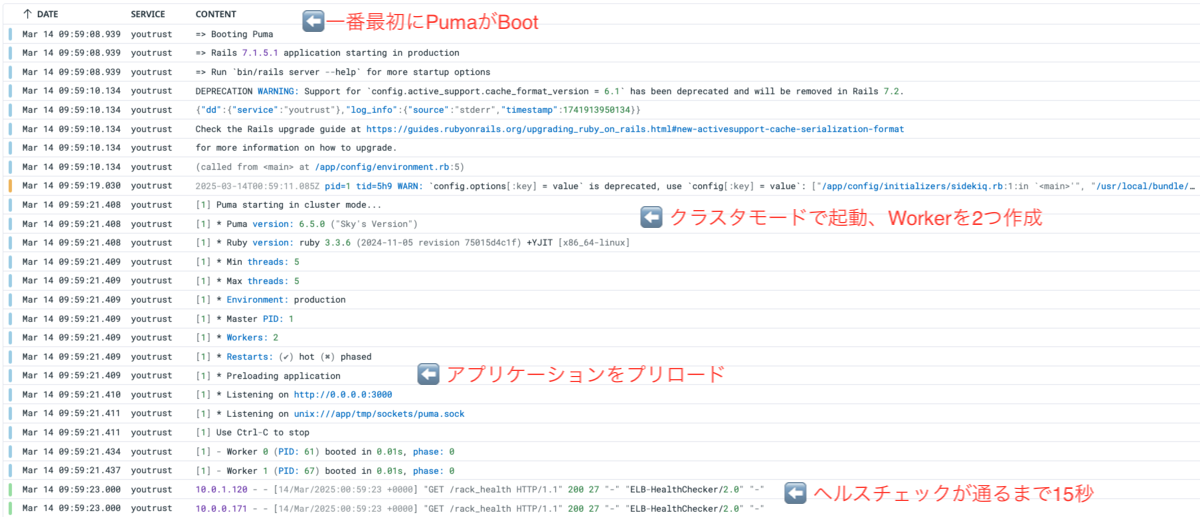
起動時間の短縮
修正前はログが記録され始めてから200ステータスになるまでに2分掛かっていましたが、変更後はヘルスチェックよりも前にPumaが起動を始め、15秒くらいと大幅に起動時間が短縮されました。💨
サイト全体が高速化
FargateでvCPUを0.5から2へ増強したことで、サイト全体が大幅に高速化し、ユーザー体験が向上しました!🥳🎉
元環境ではCPU制限により平均使用率50%でも、ピーク時には100%に達してスロットリングが発生し、処理が遅延していました。
vCPUを4倍に増やしたことで処理能力に余裕が生まれ、リクエストのキューイングが大幅に減少。
これにより、ユーザーリクエストへの応答時間が短縮され、全体のパフォーマンスが向上しました。
また、CPU使用率によるオートスケーリングを設定していますが、単体タスクの処理能力が向上したことでスケールアウト頻度が減少し、結果的にタスク数が抑えられ、予想に反してコスト削減💸にもつながりました。
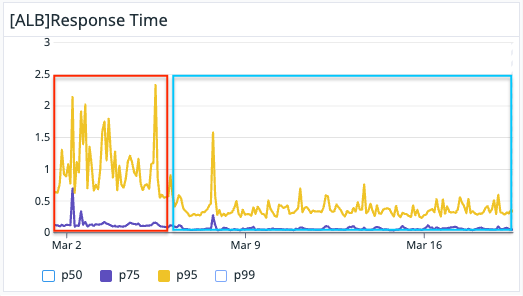
下記画像のように75 percentileはあまり変化ありませんが、95 percentileが約1.5秒から約0.5秒とレスポンスタイムが短くなっています。
学び
今回の対応を通じて、以下のことを学びました。📝
1. 障害対応プロセスの重要性
- 障害対応には一定の流れがあり、そのプロセスを体験したことは貴重な経験を得られた
通知 → 障害内容の把握 → 施策立案 → 検証 → 実装というPDCAサイクルを意識することが重要
2. オブザーバビリティの価値
- 適切なモニタリングとログ収集の仕組みにより、問題発生時に迅速に必要な情報を集約が可能になった
- 問題の可視化が解決への第一歩であることを再認識できた
3. 多角的アプローチの必要性
- 一つの問題は様々な要素が絡み合っており、単一の視点だけでは解決できない
- パフォーマンス問題は特に、インフラ、アプリケーション、設定など複数の領域から調査する必要がある
4. AIツールの適切な活用
- 今回AIツールに分析を依頼しましたが、適切な情報提供がでなければ的確な回答を得られない
- また、AIの回答を鵜呑みにせず検証する姿勢が大切
- 将来的にはDatadog Workflow Automation(Datadog の自動化機能)など用い、適切な情報を自動収集し、より効果的にAIを活用したいと考えている。
これらの学びを今後のインフラ運用や障害対応に活かしていきたいと思います。
最後に
スタートアップだからこそ自身で手を挙げればやったことがないことも挑戦できる環境が整っています! もしこのブログを読んで興味をもっていただけたら下記を覗いてみてください!