
先日SRE Kaigi 2025に弊社SREの須藤、寺井と参加してきました!
セッション、ブース共に楽しく、タメになりすぎるカンファレンスでした。
(弊サービスのYOUTRUST内でもSREコミュニティが細々運営中ですのでもしよろしければ🙌)

さて、本題ですが、今回は「Datadog導入に際し、実施したこと」を書いていこうと思います。
「公式ドキュメントを直接参照した方が早いのでは?」という方もいるかもしれませんが、Datadogの機能は幅広く各社必要な機能はバラバラです。
そのため体系的に書かれておらず、私自身どこから初めて良いのか、様々な箇所から情報収集したので弊社ではこれを実施したよというのをまとめてみようというのが経緯となります。
※ 技術的な内容というよりは実施したことの備忘録的なブログです。
- 導入背景・課題
- ゴール設定
- 実施内容
- Slack連携
- Datadog Agentの導入
- Rubyアプリケーションのトレース設定
- CloudWatch Metric Streamを設定
- ログ周り
- Terraformデプロイ環境構築
- モニタリング作成
- ダッシュボード作成
- Datadog勉強会実施
- 今後の展望
- 最後に
導入背景・課題
導入前は下記のような問題点がありました。
- データの活用が限定的
- ダッシュボードのカスタマイズ性が限られており、視覚的に見づらい部分がある。
- アプリケーション監視が十分でなく、問題点を迅速に発見するのが難しい。
- 調査プロセスの煩雑さ
- 環境ごとやAWSサービスごとに画面を切り替える必要があり、効率的な調査が難しい。
- 情報が分散しており、統合的な可視化が課題となっている。
- CloudWatch Insightsの記法が特殊で学習コストがかかる。
- アラートの柔軟性の不足
- CloudWatch AlarmではWarningレベルの設定ができず、重要度に応じた通知の調整が難しい。
- 時間帯に応じたアラートの無効化など、柔軟な運用が難しい。
上記を踏まえ、CloudWatchからDatadogへ移行することを決定しました。
ゴール設定
移行作業を任せていただけたものの私はDatadogを使用したことがありませんでした。
下記Datadogサービスを「最低限使用可能な状態にする」というざっくりとしたゴールを決め、その上で要件からタスクを絞り込んでいきました。
| No | 使用サービス | 細かな要件 |
|---|---|---|
| 1 | Dashboard | CloudWatchのダッシュボードより見やすくしつつ、表示の詳細さは維持する |
| 2 | Monitors | Warning設定を可能にする Terraformで管理する |
| 3 | Infrastructure | 各コンテナのCPUやメモリを確認可能にする タグから各環境、サービスで絞り込みを行えるようにする |
| 4 | APM | トレース情報からアプリケーションの処理を追えるようにする |
| 5 | Metrics | メトリクスの配信期間はCloudWatchと遜色ないようにする |
| 4 | Logs | 環境、サービス毎に検索可能にする メールアドレスなどのセンシティブ情報はマスクする |
実施内容
事前準備
アカウント作成
基本的な設定手順に従えば問題ないですが、注意点としては2点あります。
1. Datadogのサイトを間違えない。
2. 管理用のアカウントで作成する。後でAdminアカウントは変えられますが、最初から設定してある方が楽です。
AWSインテグレーション設定
AWSの基本メトリクス収集はインデグレーション機能で一発で設定可能です。
各環境でCloudFormationを利用し、IAM Roleを作成しました。
また、必要ないリージョンやサービスは対象外とすることで費用を少しだけ抑えられます。
Slack連携
モニタリング機能の通知に利用するSlack連携もインテグレーション機能により簡単に設定可能です。 ただ、SlackにDatadogアプリをインストールするにはワークスペースの許可設定が必要です。
Datadog Agentの導入
弊社環境はECS on Fargateで運用されているため各コンテナサービス内にDatadog Agentのサイドカーコンテナを追加しました。
基本的に公式ドキュメント通りタスク定義を変更すれば問題ありませんが、下記3点を工夫しました。
- API Keyはベタ書きせず、SSMパラメータストアから取得
- Datadog Agentが起動しない場合でもサービス全体を止めないようessential属性をfalseに変更
- Datadog固有タグを下記に決定
| Key | Value | 備考 |
|---|---|---|
| dd_service | youtrust, youtrust_admin, youtrust_worker | 各サービスで検索可能に |
| dd_source | ruby, nginx | |
| dd_env | production, sandbox | |
| dd_version | GitHubのコミットID |
Rubyアプリケーションのトレース設定
Datadog AgentのAPM環境変数をtrueにしただけではRubyアプリケーションをトレースできません。 公式ドキュメントを参考に専用のgemをインストールしてください。
CloudWatch Metric Streamを設定
DatadogからAWSへのメトリクスポーリング間隔は10分です。
しかし、重要なメトリクスはその間隔では使い物にならないためCloudWatch Metric Streamを使用することで最小2分で配送できるため設定することをお勧めします。
ただ、本機能は高額のためすぐに不具合を検知したいELB、ECS、RDSのメトリクスを設定しています。
ログ周り
Firelensコンテナ作成
Datadogではログ保存期間がデフォルトで2週間のため長期保存ログはS3へ保存する要件がありました。
そのためサイドカーコンテナとしてfluent-bitエンジンを使用したFirelensを作成し、ログの振り分け設定を行いました。
ただ、ログドライバーをawslogsからFirelensに変更するとECSのウェブコンソールからはログが見れなくなるのが微妙なポイントですね😵.
ログパイプラインの構築
Rubyのログは本来Datadogが自動で判別し、整形してくれますが、弊社環境では正しく動作せず自身で下記パイプラインを構築しました。
- Grok Parserでの正規表現によるログの整形
- APMとログの紐付けを行うtrace_idとspan_idのリマッピング
- Sensitive Data Scanner機能によるメールアドレスなどのセンシティブデータのマスク設定
Terraformデプロイ環境構築
モニタリングとユーザー、インテグレーション設定をTerraformで管理することとしました。
そのためのGitHub ActionsやGitHubリポジトリの設定を行いました。
ダッシュボードはWebコンソールから設定する方が楽であり柔軟に使用できると考え、コード管理からは除外しました。
モニタリング作成
CloudWatch Alarmを元に監視設定を行いました。
モニタリング機能のTerraformでの管理はjson形式とそのままのリソースで管理する方法があります。
詳しく解説してある資料がありますが、jsonでの管理は煩雑になりやすいと考え、弊社ではリソースをそのまま記述する方法を取っています。
独特の記法により最初は慣れないと思いますが、その際はモニタリングの編集画面のExport MonitorボタンからTerraformの記述を参考にしてください。
ダッシュボード作成
下記方針を基に画像のようなダッシュボードを作成しました。
- 元のCloudWatchダッシュボードと粒度や見方を大きく変えない
- 最初の一画面で最も重要な情報を取得可能な状態
- 下の方に折りたたみ式で詳細情報を配置(ワイドディスプレイでは右側)
- ユーザーから近いとこから順に配置
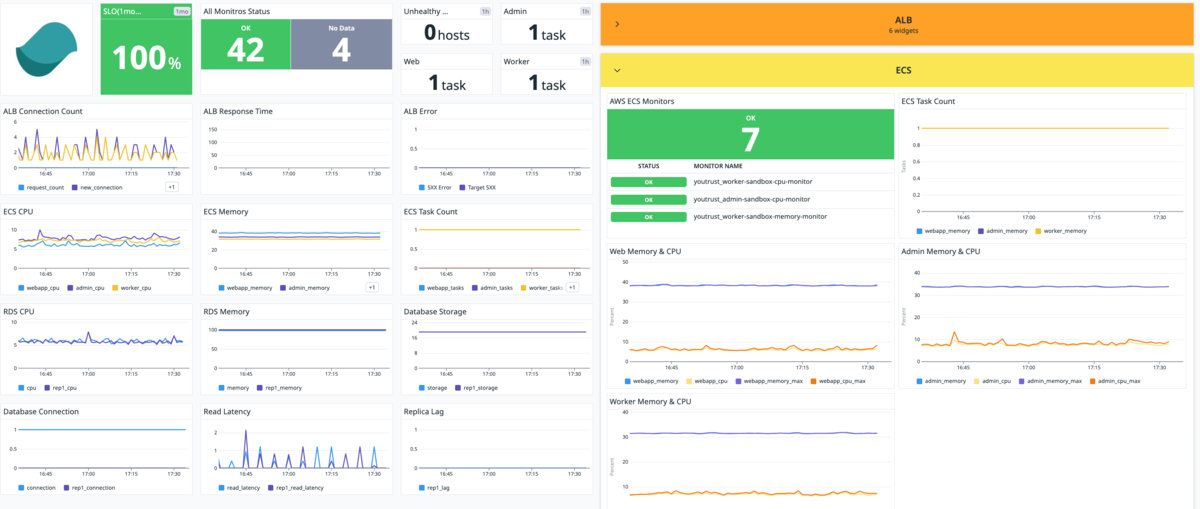
sandbox環境ダッシュボード
Datadog勉強会実施
折角設定を進めているDatadogのためSRE以外にも使用してもらいたいため社内で勉強会を実施しています!
目指すは*1オブザーバビリティを実現し、開発のパフォーマンス改善などにもDatadogが利用される世界!
今後の展望
まだまだ設定不足や足りない情報があり、Issueの選別など課題も多く山積しているため一つ一つ確実に対応していきます。
また、Datadogは超高額なツールのため費用対効果次第ですが、個人的には下記サービスも導入していきたいです!💸💸
- RUM
- Synthetic Monitoring
- Mobile Application Monitoring
- Database Monitoring
最後に
スタートアップだからこそ自身で手を挙げればやったことがないことも挑戦できる環境が整っています! もしこのブログを読んで興味をもっていただけたら下記を覗いてみてください!
*1:データに沿って誰でもデータを分析し、現状のサービス状態を把握できる状態のこと